近日,计算语言学峰会LREC2026在西班牙马略卡岛召开,会上举办的EvaHan2026古籍多模态OCR国际评测比赛吸引了各大知名院校的40多支队伍同场竞技。我院叶晨老师团队提出的双模态古籍版面分析与文字识别框架在比赛中获得冠军。该团队的核心成员为2023级计算机科学与技术专业本科生樊祺和2023级信息安全专业本科生胡捷鸣。

中文古籍承载着中华文明数千年的文化与历史信息,是传承民族文化基因的核心载体。在古籍数字化加工的过程中,将海量古籍图像转化为可检索、可计算的文本是关键一环。然而,古籍文档的排版和布局与现代印刷存在显著差异,加之古籍本身的文字形态复杂(如大量异体字)、版式多样(如双行夹注、图文混排),基于现代文档数据开发的OCR工具在处理古籍图像时往往难以达到理想效果。仅依靠人工录入,不仅耗费大量人力物力,也难以满足规模化处理的需求。因此,面向古籍的OCR研究在推动古籍的创造性转化与创新性发展方面具有重要意义。
在版面分析(Task B)任务中,团队设计了“大模型+纯视觉”双线并行的方案。针对古籍版面元素(如海量正文与极稀少印章)极其严重的“长尾分布”问题,团队在大模型微调中创新性地引入了频率感知的序列化课程学习(Curriculum Learning)机制,通过动态重放有效避免了少数类元素被模型“遗忘”。同时,面对古籍中密集的非轴对齐排版,团队平行提出HistLayout-DETR架构,通过多尺度形态学特征提取与多边形边界回归,实现了对双行夹注、印章等复杂版面元素的精准定位与提取。
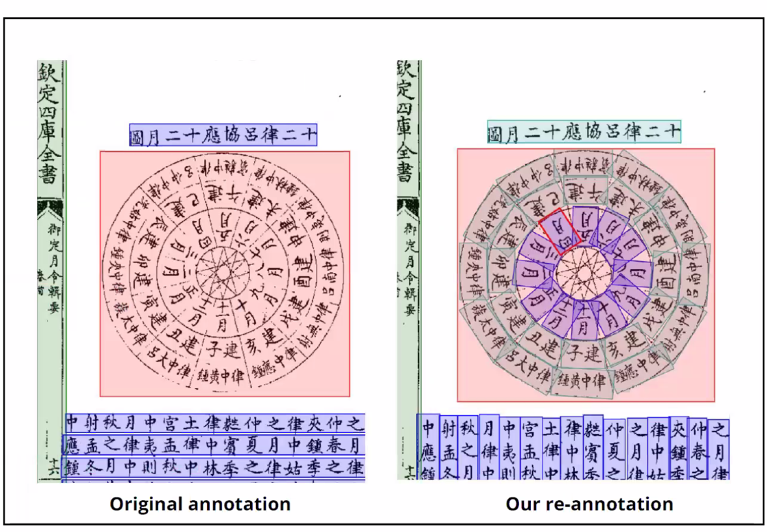
Task B版面分析任务示例
在文字识别(Task A/C)任务中,团队打破了传统OCR范式,将其重新建模为“受领域约束的视觉语言生成任务”。面对刻本(印刷体,Task A)与手写体(Task C)在字形变体与退化程度上的巨大差异,团队提出了高效的联合训练(Joint Training)方法。该方法使用LoRA技术将两类图像数据混合输入大模型进行微调。这一核心策略使得模型既能从刻本数据中汲取极其稳定的古代汉字字形与词汇先验知识,又能跨域泛化,大幅提升了模型对手写体中残损、连笔、墨迹晕染等退化笔画的鲁棒性。配合团队设计的结构化提示词,框架完美保留了古籍从右至左的阅读顺序与繁体字形,消除了大模型常见的“繁简转换”或“过度解释”等幻觉问题。
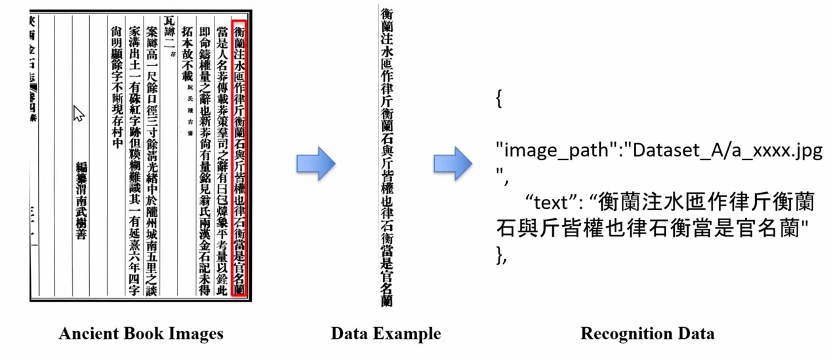
Task A文字识别(印刷体)任务示例
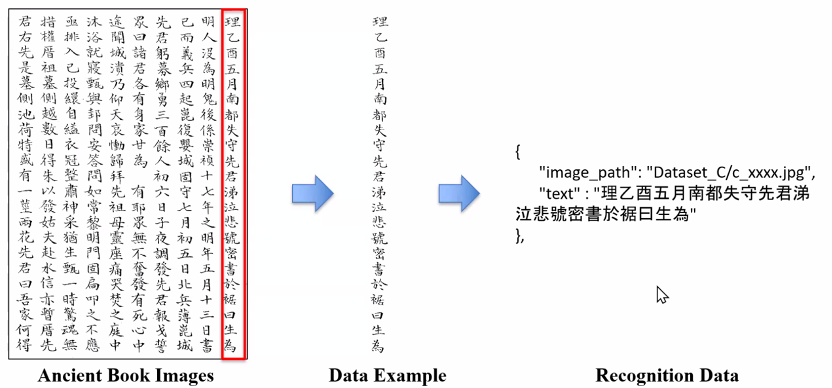
Task C文字识别(手写体)任务示例
基于上述深度的底层算法创新,团队在文字识别任务中分别斩获了0.9736的最佳得分(印刷体)以及0.9571的最佳得分(手写体),获得竞赛冠军。
未来,团队将继续深耕古籍数智化技术,助力让沉睡在典籍中的中华文明智慧“活起来”,更好地服务于当代社会与全球文化交流。
祝贺获奖同学!
祝贺叶晨老师团队!